2.1 顺序表
Note
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。 数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
数组(array) 是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。图 2-1 展示了数组的主要概念和存储方式。
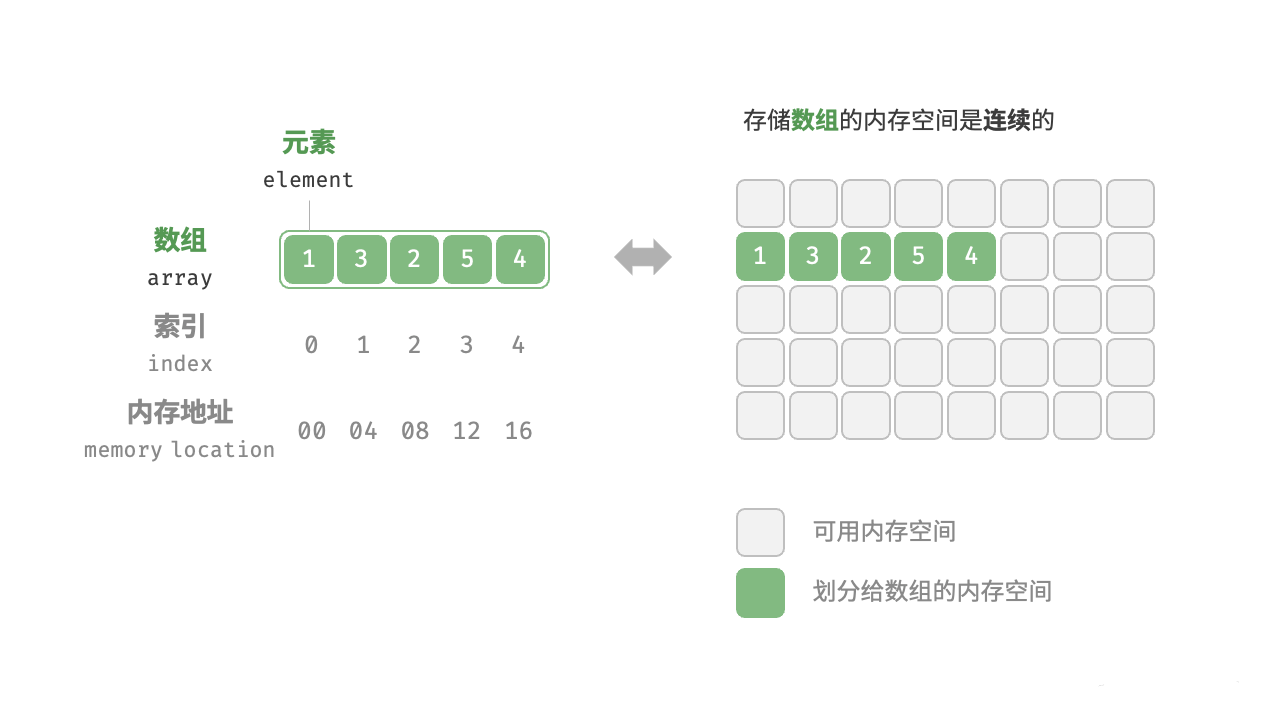
2.1.1 数组
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
| array.cpp | |
|---|---|
1 | |
- ElemType:是我们要存放的数组元素的
类型,类型可以是int,float,double,char,或者其他可以使用的数据类型; - name:是用来表示数组的,称为
数组名; - size:当前数组可以存放的
最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
| array.cpp | |
|---|---|
1 2 3 | |
请注意
后续中提到的所有
索引或下标 都是从 0 开始计数。位序或第几个 都是从 1 开始计数。
1 数组初始化
我们可以根据需求选用数组的两种初始化方式:无初始值、给定初始值。在未指定初始值的情况下,大多数编程语言会将数组元素初始化为 :
| array.c | |
|---|---|
1 2 3 | |
| array.cpp | |
|---|---|
1 2 3 4 5 6 7 | |
| array.py | |
|---|---|
1 2 3 | |
| array.java | |
|---|---|
1 2 3 | |
2 数组访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(首元素内存地址)和某个元素的索引,我们可以使用图 4-2 所示的公式计算得到该元素的内存地址,从而直接访问该元素。

观察右图,我们发现数组首个元素的索引为 0,这似乎有些反直觉,因为从1开始计数会更自然。但从地址计算公式的角度看,索引本质上是内存地址的偏移量。首个元素的地址偏移量是0,因此它的索引为0是合理的。
在数组中访问元素非常高效,我们可以在O(1)时间内随机访问数组中的任意一个元素。
| array.c | |
|---|---|
1 2 3 4 5 6 7 8 | |
| array.cpp | |
|---|---|
1 2 3 4 5 6 7 8 | |
| array.py | |
|---|---|
1 2 3 4 5 6 7 | |
| array.java | |
|---|---|
1 2 3 4 5 6 7 8 | |
3 数组插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如图 2-4> 所示,如果想在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
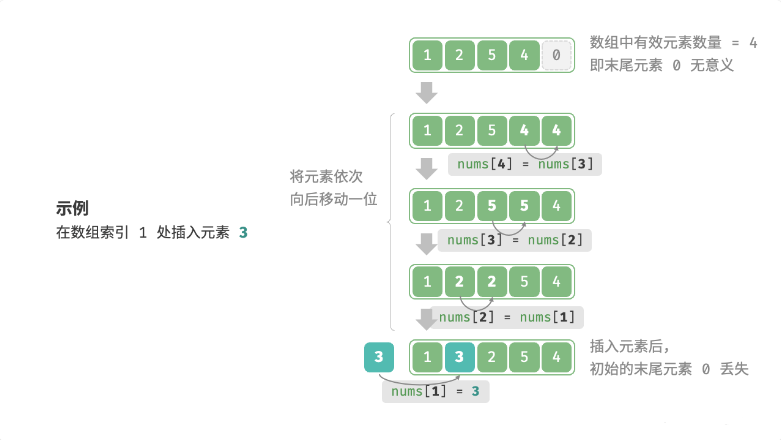
| array.c | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
| array.cpp | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
| array.py | |
|---|---|
1 2 3 4 5 6 7 | |
| array.java | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
4 数组删除元素
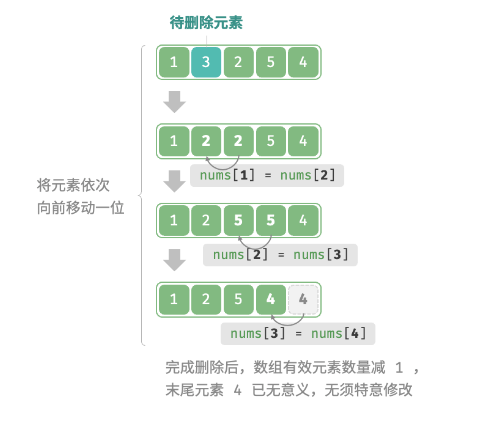
同理,如右图所示,若想删除索引
i处的元素,则需要把索引i之后的元素都向前移动一位. (1)
请注意,删除元素完成后,原先末尾的元素变得“无意义”了,所以我们无须特意去修改它.
| array.c | |
|---|---|
1 2 3 4 5 6 7 8 | |
| array.cpp | |
|---|---|
1 2 3 4 5 6 7 | |
| array.py | |
|---|---|
1 2 3 4 5 | |
| array.java | |
|---|---|
1 2 3 4 5 6 7 | |
请注意
总的来看,数组的插入与删除操作有以下缺点。
1. 时间复杂度高: 数组的插入和删除的平均时间复杂度均为O(n),其中n为数组长度。2. 丢失元素: 由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失.
3. 内存浪费: 我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做会造成部分内存空间浪费.
5 数组遍历
在大多数编程语言中,我们既可以通过索引遍历数组,也可以直接遍历获取数组中的每个元素:
| array.c | |
|---|---|
1 2 3 4 5 6 7 8 | |
| array.cpp | |
|---|---|
1 2 3 4 5 6 7 8 | |
| array.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
| array.java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
2.1.2 顺序表的介绍
提示:
我们前面已经介绍了数组的知识点:
1. 数组是一种数据结构,用于存储相同类型的元素的集合.2. 由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失.
那么数组和线性表的关系是什么呢?
1. 线性表是一种数据结构,其中元素排列成一条线一样的顺序.2. 这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继.
3. 线性表包括顺序表(数组实现)和链表等.
数组是一种实现线性表的方式之一.线性表可以通过数组来实现,也可以通过链表等其他结构来实现.因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一.
通过数组实现的线性表称为顺序表1 顺序表的定义
线性表的顺序存储类型结构如下:
1 2 3 4 5 6 7 8 | |
定义了一个结构体SqList,包含两个成员变量:data和length.
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素.
2 顺序表的初始化
1 2 3 4 | |
这个函数的作用是将传入的顺序表L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
3 在顺序表中插入元素
下面代码显示的是在顺序表L的第i个位置插入元素e
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
插入顺序表 | 可视化运行
4 在顺序表中删除元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单. 我们只需要在当前存放元素的长度 - 1> (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
删除顺序表 | 可视化运行
时间复杂度:
- 最好情况: 如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为O(1),即常数时间复杂度.这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素.
- 最差情况: 如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置.在最坏情况下,这个移动过程需要线性地遍历和移动n个元素,其中n是顺序表中的元素个数.因此,最坏情况下的时间复杂度为O(n).
- 平均情况: 平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为O(n).
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
时间复杂度:
- 最好情况: 要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为O(1) ,即常数时间复杂度.
- 最差情况: 要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中.在这种情况下,时间复杂度为O(n),其中n是顺序表中元素的个数.
- 平均情况: 平均情况的时间复杂度通常是O(n),因为平均而言,我们可以认为要查找的元素在顺序表的中间位置.但是在大O表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是O(n).
2.1.3 顺序表数组实现的优点与缺点
优点
- 随机访问速度快: 由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 O(1).这使得数组在需要频繁随机访问元素的情况下非常高效.
- 节约空间: 相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间.
- 缓存友好: 由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势.
优点
- 固定大小: 数组的大小是固定的,一旦创建后就不能动态改变.如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销.
- 插入和删除操作效率低: 在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 O(n).这使得数组在频繁插入和删除操作的场景下效率较低.
- 不适合存储变长数据: 由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求.