2.3 双链表
Info
单链表结点中只有一个指向其后继的指针,使得单链表只能从前往后依次遍历.要访问某个结点的前驱(插入、删除操作时),
只能从头开始遍历,访问前驱的时间复杂度为 O(n).
为了克服单链表的这个缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其直接前驱和直接后继.
双链表的主要特性
- 双向遍历由于每个节点都有前后两个指针,因此可以在列表中双向遍历,无需像单链表那样只能从头节点开始向前遍历。
- 插入与删除的便捷性:在双链表中插入或删除一个节点时,只需改变相应节点的前后节点的指针指向即可,操作相对简单高效。
数据结构
- data:数据域,也是节点的值
- prior:指针域,指向前一个结点的指针
-
next:指针域,指向下一个结点的指针
Dlinked_list.c 1 2 3 4 5
/* 双链表中查找值为 target 的首个节点 */ typedef struct DNode { int data; // 数据 struct DNode *prior, *next; // 前驱和后继指针 } DNode, *DLinkList;

Tip
双链表在单链表结点中增加了一个指向其前驱的指针 prior ,因此双链表的按值查找和按位查找的操作与单链表的相同.但双链表在插入和删除操作的实现上,与单链表有着较大的不同. 这是因为“链”变化时也需要对指针 prior 做出修改,其关键是保证在修改的过程中不断链. 此外,双链表可以很方便地找到当前结点的前驱,因此,插入、除操作的时间复杂度仅为 O(1).
双链表的基本操作实现
单链表的节点在需要时
由于链表节点是在需要时分配的,可以避免数组因初始化大小不确定而造成的内存浪费。例如,如果数组大小初始化过大,未使用的部分将浪费内存;若初始化过小,则可能需要频繁重新分配和复制。
每个节点需要一个指针域来存储对下一个节点的引用,这意味着相比于数组,单链表在每个节点上都会有额外的内存开销。对于存储小数据的场景,这个开销相对较大,可能导致内存利用率下降。
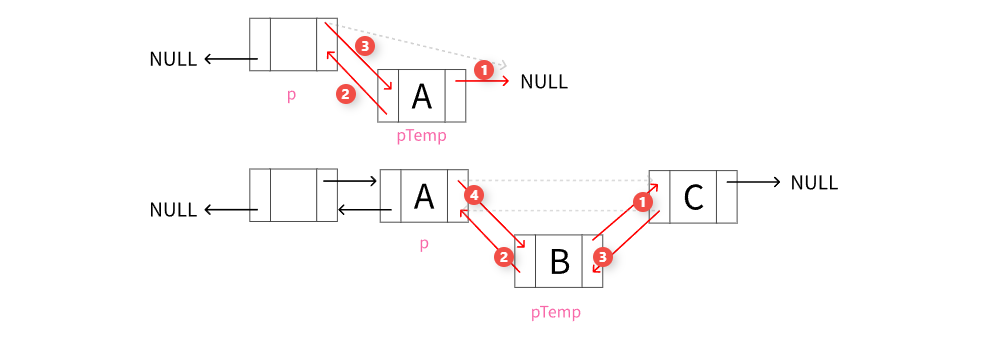
按位序插入结点
该函数用于在双向链表中按指定位置插入一个新元素。(注意区分位置和下标:位置从1开始,下标从0开始)
在位置 i 插入元素 e,其中 i=1 表示插入到表头, i=length+1 表示插入到表尾。
重点注意下链表为空和不为空时的处理逻辑
| linked_list.c | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
| linked_list.cpp | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
| linked_list.py | |
|---|---|
1 | |
| linked_list.java | |
|---|---|
1 | |
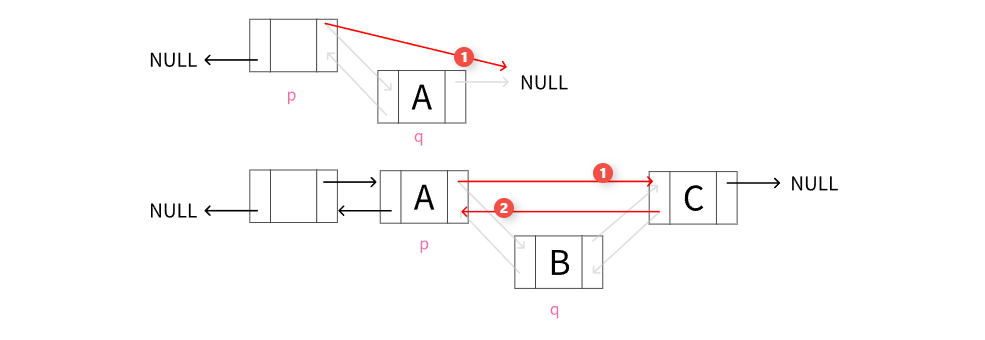
按位序删除结点
该函数用于按位序删除节点的功能。具体来说,当参数 i 为 1 时,删除链表的 头节点 ;当 i 等于链表长度时,删除链表的 尾节点 。
重点注意下链表为空和不为空时的处理逻辑
| linked_list.c | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
| linked_list.cpp | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
| linked_list.py | |
|---|---|
1 | |
| linked_list.java | |
|---|---|
1 | |